
Scaling Law in Robotics
At Covariant, we see that as we train RFM-1 on more data, our model's performance improves predictably, reflecting Scaling Law in robotics.
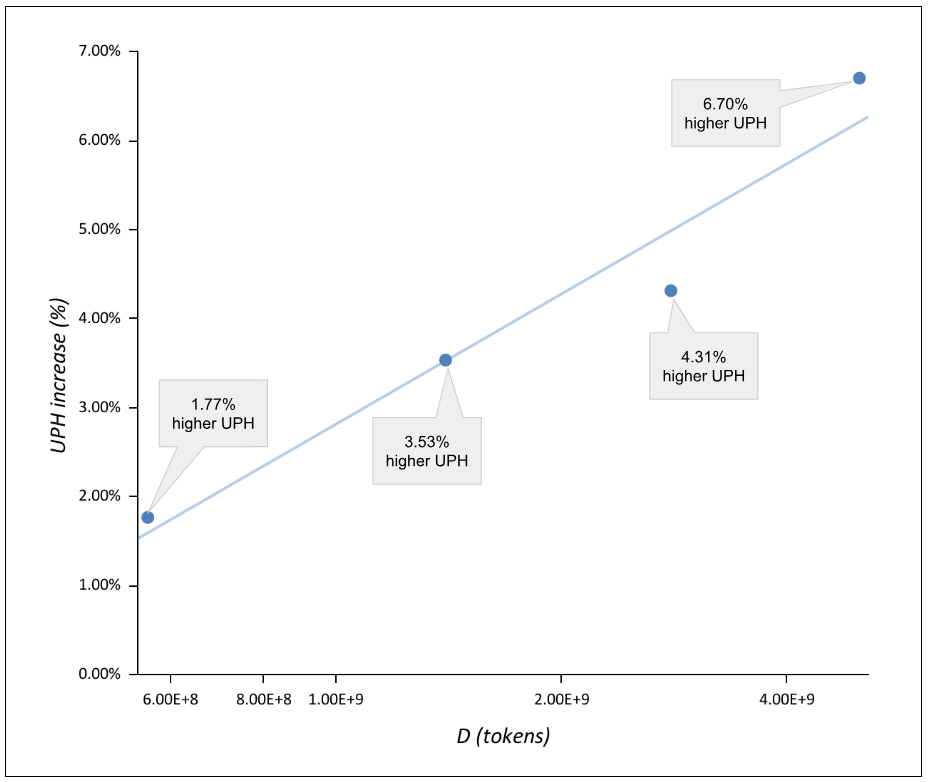
For example, our research data indicates that by increasing the size of the dataset on which RFM-1 is trained, the quality of grasps generated increases. With better grasp options, pick retries can be reduced by 43%. As more data is used to train RFM-1, fewer pick retries result in increasingly higher robotic picking speed (UPH or Units Per Hour).




